
Machine-generated text has been fooling humans for the last four years. Since the release of GPT-2 in 2019, large language model (LLM) tools have gotten progressively better at crafting stories, news articles, student essays and more, to the point that humans are often unable to recognize when they are reading text produced by an algorithm. While these LLMs are being used to save time and even boost creativity in ideating and writing, their power can lead to misuse and harmful outcomes, which are already showing up across spaces we consume information. The inability to detect machine-generated text only enhances the potential for harm.
One way both academics and companies are trying to improve this detection is by employing machines themselves. Machine learning models can identify subtle patterns of word choice and grammatical constructions to recognize LLM-generated text in a way that our human intuition cannot.
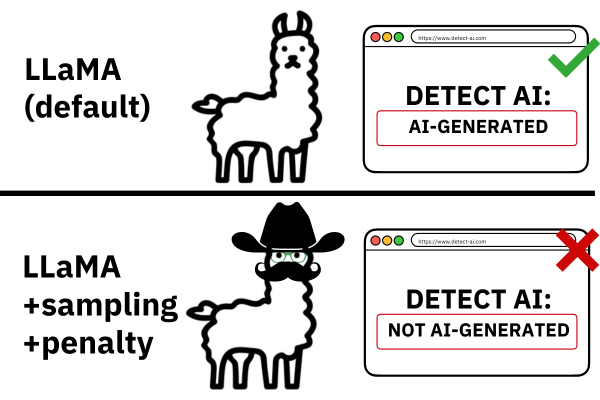
Today, many commercial detectors are claiming to be highly successful at detecting machine-generated text, with up to 99% accuracy, but are these claims too good to be true? Chris Callison-Burch, Professor in Computer and Information Science, and Liam Dugan, a doctoral student in Callison-Burch’s group, aimed to find out in their recent paper published at the 62nd Annual Meeting of the Association for Computational Linguistics.